-

Egyptian Scarab
Lion Hunt Scarab from Amenhotep III
-

Always Available Distributed Inventory Solution Using Datastax
Retail operations are increasingly integrating on-line and brick and mortar operations, including inventory management. With options such as ‘buy on-line and pick-up in store’ becoming popular, a scalable, distributed, always available, real-time inventory system is needed.
-
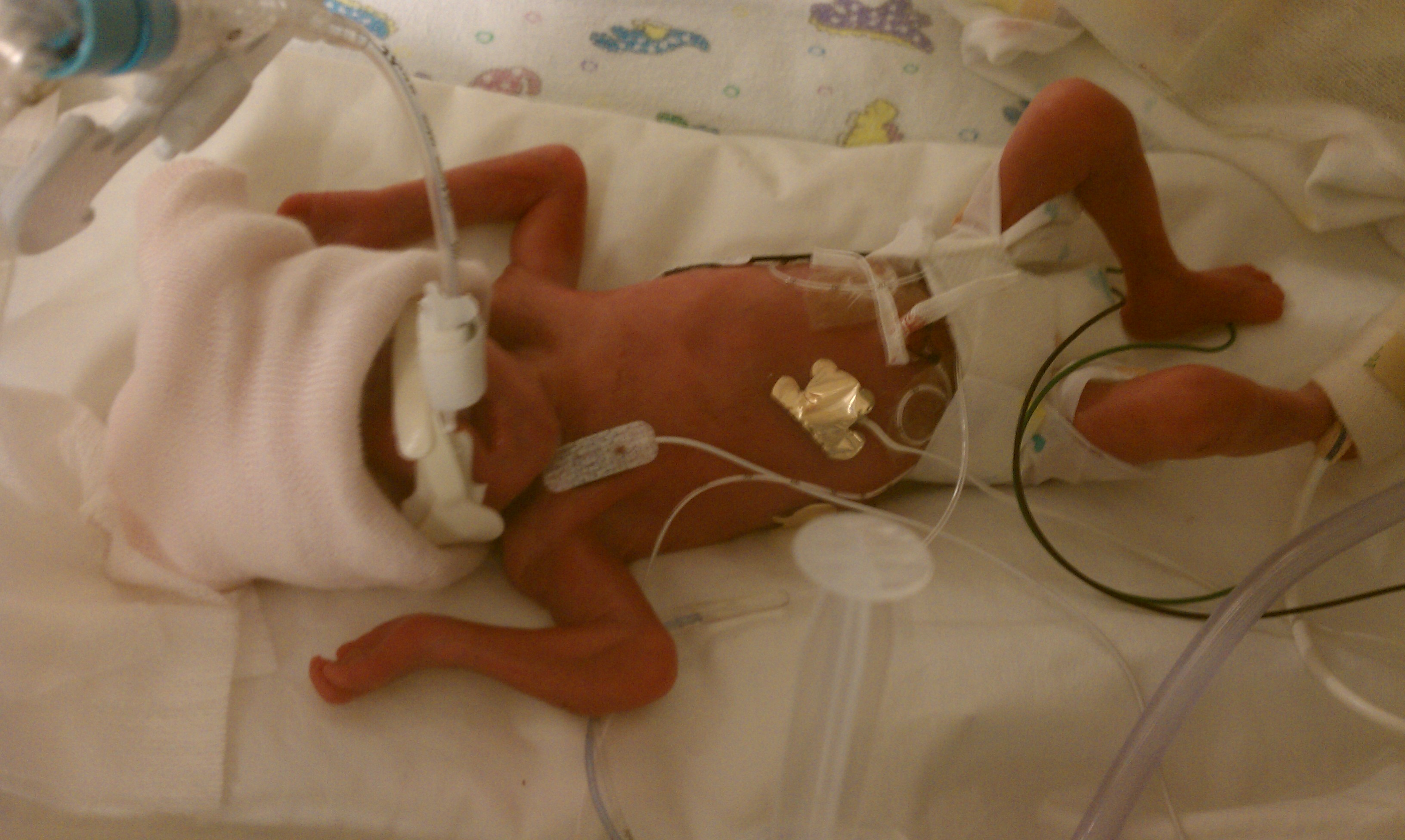
My Miracle
The events of August 23rd, 2010. “Don’t worry, about a thing…” My ringtone blares out Bob Marley as the tech squeezes out a splat of aloe gel on Monica’s belly. “Cause every little thing gonna be all right.” It was the last day of our vacation, and we had just gotten back home to Austin.…
Got any book recommendations?